
| 所属 | 大学院情報理工学研究科 情報学専攻 |
| メンバー | 柳井 啓司 教授 |
| 所属学会 | 情報処理学会、電子情報通信学会、人工知能学会、米電気電子学会コンピュータ学会(IEEE Computer Society)、米コンピュータ学会(ACM) |
| 研究室HP | https://mm.cs.uec.ac.jp/ |
| 印刷用PDF | 柳井啓司 研究室(PDF:1.2MB) |
掲載情報は2026年5月現在

画像認識、画像理解、物体認識、機械学習、情報検索
ディープラーニング(深層学習)を基盤とした大規模言語モデル(LLM)の発展によって生成AI(人工知能)が登場し、文章や画像、音声、映像などの認識や生成が誰でも可能な時代になりました。生成AIは今やさまざまな領域で不可欠な技術となり、AIの研究開発のスピードやそのアプローチも加速度的に変化しています。AIブームを背景に研究者人口が増え、さらにビジネスの領域でも世界のテック企業が次々と参入していることで開発競争が過熱しています。
このように急速に進化する研究分野において、柳井啓司教授は長年、画像や映像の認識・生成とその応用システムの開発に取り組んできました。生成AIをはじめとする近年の技術革新により、「食事内容の認識や質感の変換など、これまで研究してきた技術のほとんどが現在では実現している」と柳井教授は言います。毎日100本以上の論文が発表され、1年前の研究はすでに“過去の研究”とみなされるそうです。
生成AIの核となるLLMは、プロンプトと呼ばれる指示文を入力して文章を生成する仕組みです。そこに画像認識モデルや画像生成モデルが導入されたことで、プロンプトだけで複雑な画像を生成したり、画像を入力し、その画像に結びついた膨大な言語知識をもとに、関連情報を文章で出力したりすることが可能になっています。
このマルチモーダル生成AI(LMM)の誕生によって、テキストや画像、音声、音楽、映像などが自在に入出力できるようになりました。例えば、食事の風景を撮影した画像を入力すると、AIがそのメニュー名やレシピ、栄養学的な観点からのアドバイスなどを瞬時に提示してくれるでしょう

柳井研究室では、LMMのオープンソースモデルを活用し、推論による画像の領域分割や、画像の3次元復元といった最新の生成AIでも不可能な範囲の研究を進めています。領域分割では、食事の画像から「ご飯」「肉」などの領域を抜き出すという既存の技術をさらに発展させ、「酸っぱい部分はどこか」といった推論を含むタスクを与えた場合でも、高い精度で領域分割を可能にしました。
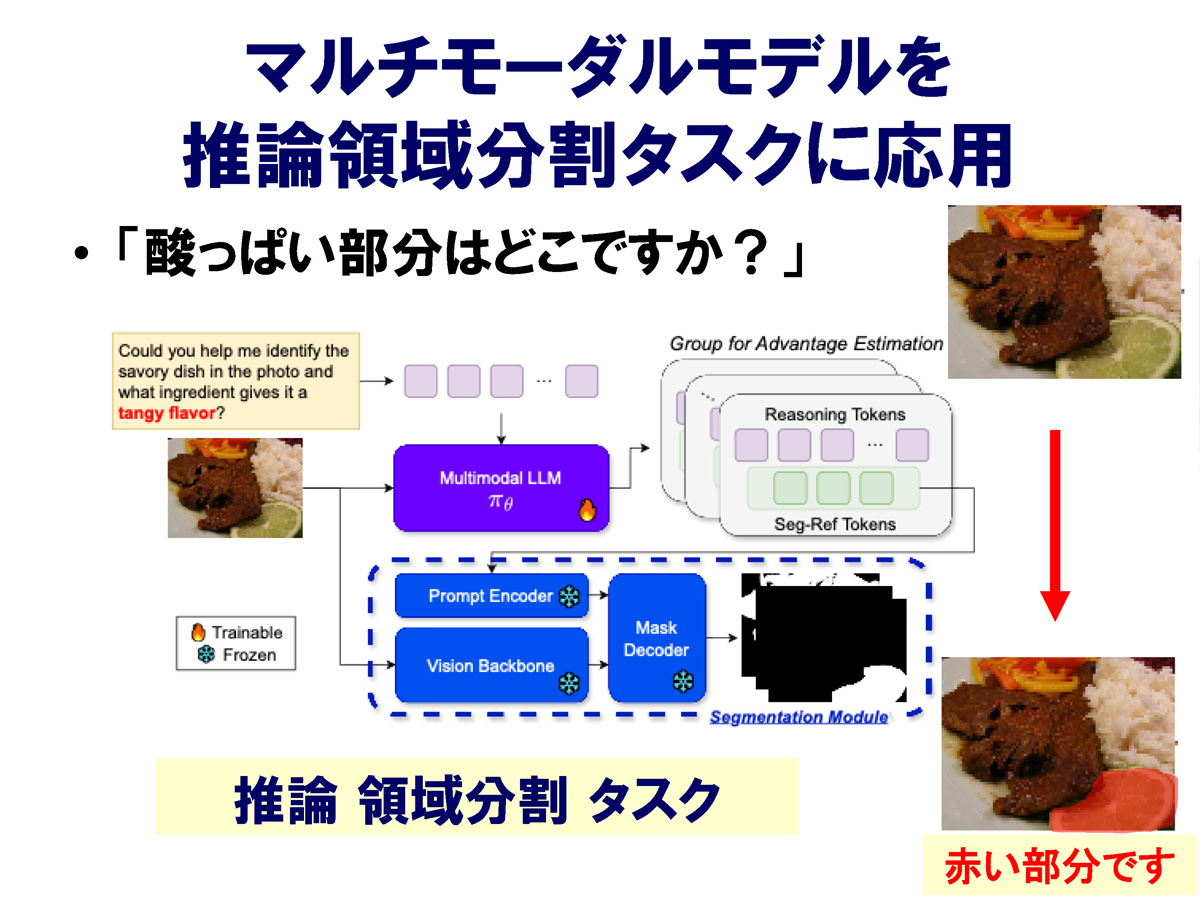
また、ある対象物の前方からの撮影画像をもとに、その物体の「裏側」を推定し、3次元画像として復元する技術や、ある背景画像に物体の画像を自然に埋め込む画像編集技術なども開発しています。さらに、言葉によって文字のフォントスタイルを装飾したり、そのスタイルを自在に変換したりする画像生成技術も発案し、LMMの機能を拡張するさまざまな技術を提案しています。

そのほか、食事画像の認識や生成、質感の変換といった編集技術も長年にわたり開発してきました。過去には食事メニューをスマホで撮影し、その料理を認識するだけでなく、摂取カロリーまで推定する「リアルタイム食事カロリー量推定アプリ」などを提案しています。近年では、目の前の食事を別のメニューにリアルタイム変換する「食事変換AR(拡張現実)」として、実際には小盛りの食事を、“大盛りの食事”に変換したり、カレーの画像を見ながら白いご飯を食べると「カレーの味がする」といった疑似体験を提供したりしています。

これは感覚知覚が別の感覚知覚によって影響を受ける現象で、「クロスモーダル効果」と呼ばれています。過去の経験が想起され、味覚が視覚によって影響を受けることから、そうした感覚を持たせることが可能になるのです。めったに食べられないような食事を疑似的に味わったり、食事制限があったりする場合に、食べたいものを食べた気にさせることができます。2025年に日本で開かれた「大阪・関西万博」では、開発したリアルタイム食事変換アプリ『Magical Rice Bowl』の最新版を披露しました。ほかにも、醤油ラーメンの画像を「イカスミラーメン」や「ピザラーメン」といった珍しいメニューに変換したり、実在しない「妖怪ラーメン」を生成したりといったように、言葉を入力するだけで多様な画像を作り出すことができます。
歴史を振り返れば、コンピュータと人間の“知性の対決”は、長らく科学技術における大きなテーマでした。1997年、チェスの試合で人間がコンピュータに破れた時は、世界中に衝撃が走りました。2015年には、画像認識の分野でも「1000種類の画像認識テスト」において、人間が初めてコンピュータに敗北しました。これは2012年にディープラーニングを画像認識に応用したアプローチが登場したことにほかなりません。ディープラーニングとは、コンピュータ上に人間の脳を模倣した学習型の多層ネットワークを構築する機械学習の一手法で、膨大なデータを学習させることで、極めて高い性能を引き出せるのが特徴です。
これを境に、画像認識の基本手法はほぼすべて、ディープラーニングを使った技術に置き換わりました。それは「画像認識におけるパラダイムシフト」(柳井教授)であり、その後、コンピュータによる画像認識性能は年々向上し、2015年に95%以上の認識性能を達成したことで、人間の能力を超えるに至ったのです。
そこに来て、生成AIが出現し、AI分野のみならず、社会そのものをAIがガラリと変えようとしています。かつては労力を要していたデータの収集も容易になり、またプログラムも生成AIで書けるようになっています。「現在では、生成AIの基盤モデルをいかに使いこなすかが最先端研究の中心になっている」と柳井教授が語るように、AIをどう生かしていくかが、専門家だけでなく、人類共通のテーマとなっています。
【取材・文=藤木信穂】